ここ3日ほど、気が乗らないので、 ここまでの研究成果の断片をこの場でまとめる.
Identifying sections in scientific abstracts using conditional random fields (2008)
PubMed とは医学系文献 (主に論文) のオープンなアクセスサービス. 論文要旨 (アブスト) にラベルがいちいち付いているのが特徴.
ここで、ラベルとは、
などのこと. つまり、アブストのこの文はBACKGROUNDを説明した文である、などとラベル付が為されている.
実際にはラベルはもっと多くあって
などなど、沢山あるが、 ラベルの種類としては大量にあってもそのラベル付がなされた文自体は少ないので、 先ほど挙げた4つだけがあるものとする.
Minimally Invasive Monitoring of Chronic Central Venous Catheter Patency in Mice Using Digital Subtraction Angiography (DSA). - PubMed - NCBI の Abstract など. (これは実際に学習事例に含んでいる)
"アブストが文の列として与えられるので、ラベル付をせよ"
いわゆる、系列ラベリングと呼ばれるタスクである. 系列ラベリングを解くための学習器として、 隠れマルコフモデルがあるし、 元ネタのCRFがある. しかし、 ここでは次のようにさらに問題を簡単化する.
"アブストに出現した文が一つ与えられるので、ラベル付をせよ"
これは文一つを対象にした、文書分類である.
いわゆる系列ラベリングでは、前後の情報を使うことができる. たとえば、この文は先頭 (文章の頭) だから BACKGROUND で有りやすい、 この文は先の文が BACKGROUND だから次はBACKGROUND であるか、または、METHOD でありやすい、など。
実際、 BACKGROUND -> METHOD -> RESULT -> CONCLUSION という遷移がかなり多い. 簡単化した方の問題では、この情報を使わせないことにする. (問題を簡単化したのであって、解きやすくしたわけではない)
文章分類なので、以下のような素性を用いて、線形SVMを学習させることにする. ただし、学習器は、分類したいクラスごとに作成する.
これら素性をそれぞれ用いたものを比較する. 素性に何を使うか以外は全て同じ条件である.
ただし、ここでは 分類されたい4つのクラスそれぞれに対して、分類器を作成する. 即ち、「BACKGROUNDであるかどうかを二値分類する分類器」、「METHODであるかどうかを〜」、、である.
最終的に、それぞれの二値分類の結果のF1スコアの平均を取る. そういうわけで、それぞれの分類について使う素性は、同じ bag-of-words であっても、 同じ words を用いる必要はない. どの words を用いるかは、あとで特徴選択をするのだが、 それぞれのクラスに対して、カイ自乗 でトップいくつかを取る.
元ネタ見たら、CRFでやってるので、当たり前だけど、多値分類する分類器を一つ作ってAccだけで議論してるなあ。合わせるなら実験またやり直さなくちゃ。 実の所、素性としての良さを比較したいだけなので、これはこれでいいんだけどね。 どうせ、そもそも系列ラベリングを文書分類にするなって話だし。
訓練事例において、3度以上出現した単語を全てかき集める. BACKGROUNDのための分類器で素性とする単語は全て、 訓練事例において、BACKGROUNDの文だけから単語を集める (といっても全体としてはかなり重複してる). ただし、いわゆるストップワードとされるものは除く.
訓練事例で出現した、重複を除いた単語数は次の表:
| class | words |
|---|---|
| BACKGROUND | 20616 |
| CONCLUSION | 16467 |
| METHOD | 24472 |
| RESULT | 33445 |
| all | 44497 |
BACKGROUND の為に用いる words をカイ自乗値が高い順に挙げると次のよう (都合上、単語の後ろに_区切りで品詞タグがついてるが、これは見ていない):
cat -n BACKGROUND| head -30
1 were_VBD
2 %_NN
3 is_VBZ
4 -LRB-_-LRB-
5 -RRB-_-RRB-
6 be_VB
7 =_JJ
8 may_MD
9 P_NN
10 was_VBD
11 p_NN
12 are_VBP
13 <_JJR
14 been_VBN
15 has_VBZ
16 significantly_RB
17 using_VBG
18 aim_NN
19 study_NN
20 have_VBP
21 this_DT
22 95_CD
23 that_IN
24 should_MD
25 CI_NN
26 had_VBD
27 in_IN
28 suggest_VBP
29 to_TO
30 ;_:were とか is は意味わからん. % はもしかしたら関係あるか? でも数値を出すのなら RESULT だよなあ。 特にBACKGROUNDっぽいのは study、aim、significantly とかかな.
で、RESULTの単語リストを見てて思ったんだけど、 よく考えたら負の方向に効く単語であっても、 カイ自乗値は高くなる. しかも単語はBACKGROUND中の単語とかなり重複している. そういうわけで、実は BACKGROUND の単語リストとかなり一致する.
面白くないので掲載はしない.
同様に、BACKGROUNDの為の分類器では、 訓練事例のBACKGROUNDの中に出現する n-gram (n=1,2,3,4,5) を素性として用いる. 膨大なので、出現数 3 以上でフィルタリングする. それでも膨大である. ストップワードを取り除くことはしない.
BACKGROUND 中のn-gram でカイ自乗値の大きいのからそーっとソートしたもののトップ30を挙げる (行頭の数字は、n-gram の n):
head -n 30 BACKGROUND.sorted | awk '{ $2=""; print $0 }'
2 -RRB-_-RRB- ._.
3 -RRB-_-RRB- ._. __EOS__
2 was_VBD to_TO
2 %_NN -RRB-_-RRB-
3 study_NN was_VBD to_TO
2 of_IN this_DT
3 of_IN this_DT study_NN
2 study_NN was_VBD
2 -RRB-_-RRB- is_VBZ
2 95_CD %_NN
4 of_IN this_DT study_NN was_VBD
3 this_DT study_NN was_VBD
4 this_DT study_NN was_VBD to_TO
5 of_IN this_DT study_NN was_VBD to_TO
2 this_DT study_NN
2 aim_NN of_IN
2 The_DT aim_NN
3 __BOS__ The_DT aim_NN
3 The_DT aim_NN of_IN
4 __BOS__ The_DT aim_NN of_IN
2 -LRB-_-LRB- P_NN
2 is_VBZ a_DT
3 aim_NN of_IN this_DT
2 has_VBZ been_VBN
2 p_NN <_JJR
4 The_DT aim_NN of_IN this_DT
5 __BOS__ The_DT aim_NN of_IN this_DT
2 may_MD be_VB
4 aim_NN of_IN this_DT study_NN
2 __BOS__ We_PRPそれっぽそうなのとしては、 of this study や aim of (this). p < なんてのはたぶん 統計値であって、いかにも RESULT だ.
各々で、素性をカイ自乗値でソートしてあるので、上位 \(f\) 個を用いた場合の結果を示す.
一般に、特徴選択の極意は、適切な汎化である. 即ち、多いほど良いというのは素人であって、過学習を引き起こす. 実際に、素性を増やすほど、始めのうちは結果は良くなっていくが、あるところで頭打ちになり、緩やかに、結果が悪くなっていく. 「説明子」は必要最小限であるほど良い.
| f | BCK | METH | RESLT | CONCL | macroF1 | microF1 |
|---|---|---|---|---|---|---|
| 1 | 0.0 | 39.8 | 4.2 | 0.0 | 11.0 | 11.7 |
| 10 | 43.8 | 47.5 | 54.2 | 37.7 | 45.8 | 47.4 |
| 100 | 66.6 | 71.0 | 72.9 | 50.5 | 65.3 | 67.3 |
| 1000 | 77.2 | 83.5 | 82.6 | 64.6 | 77.0 | 78.6 |
| 2000 | 79.5 | 84.6 | 83.9 | 66.7 | 78.7 | 80.2 |
| 5000 | 79.4 | 86.0 | 85.3 | 67.4 | 79.5 | 81.2 |
| 10000 | 78.5 | 85.4 | 85.0 | 67.5 | 79.1 | 80.7 |
| 20000 | 76.7 | 84.2 | 84.1 | 66.8 | 77.9 | 79.6 |
こないだのセミナー発表のときの2倍くらいスコア上がった…
| f | BCK | METH | RESLT | CONCL | macroF1 | microF1 |
|---|---|---|---|---|---|---|
| 1 | 0.0 | 0.0 | 35.8 | 0.0 | 8.9 | 12.8 |
| 10 | 24.8 | 3.2 | 44.0 | 0.0 | 18.0 | 22.0 |
| 100 | 47.1 | 32.8 | 55.1 | 31.3 | 41.6 | 43.6 |
| 1000 | 68.9 | 74.3 | 75.1 | 54.0 | 68.1 | 70.0 |
| 2000 | 71.6 | 78.1 | 77.3 | 57.2 | 71.1 | 72.9 |
| 5000 | 75.2 | 81.6 | 80.9 | 61.8 | 74.9 | 76.6 |
| 10000 | 76.9 | 82.8 | 82.2 | 63.5 | 76.4 | 78.1 |
| 20000 | 76.6 | 83.2 | 83.2 | 64.2 | 76.8 | 78.6 |
ん???? bag-of-words よりずっと良いのを期待してたが
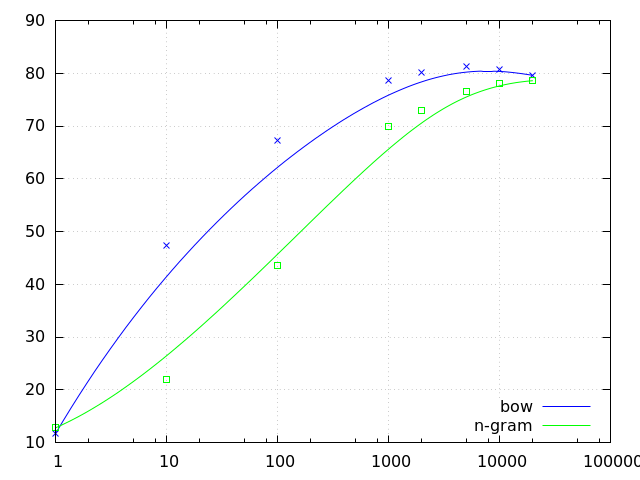
素性数毎で結果を見ることの真髄としては、 上限を心の中で見積もることだと思う. bag-of-words の素性数 (=単語数) とn-gram の素性数をそのまま比較してもあれだ. それぞれのベストパフォーマンスを比較してこそだと思う.
(https://twitter.com/cympfh_out/status/660175599336488960)
点は実データのプロット. 曲線はベジエ近似 (近似である).
bag-of-words (青) は 81% に上限がありそう. n-gram はこのグラフの範囲だと 78.6% が最大で、もうちょっと右まで行けば上がるかもしれない. でも (勝手なことを言うと) たぶん青は超えない.
素性を目で見ると、n-gram の方が、 単語一つを見るよりも、情報を多く持ってるので、 分類に効きそうにも思えたけれど、 そうでもない.